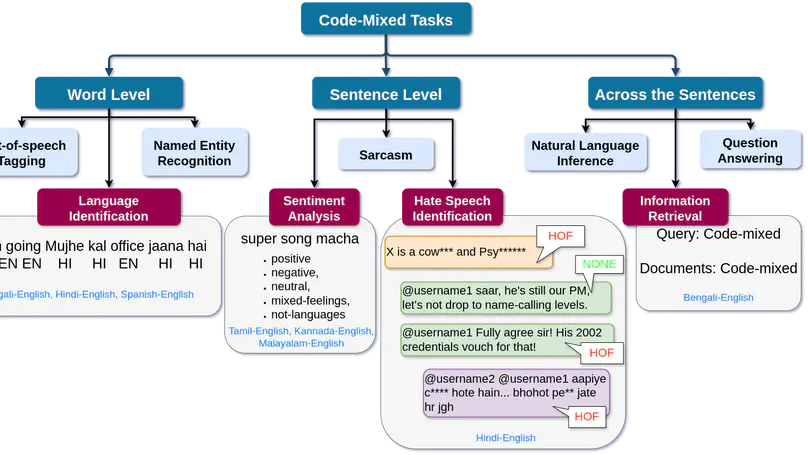
Social media has witnessed a tremendous boom over the past few years, which has in turn generated vast quantities of user-generated content. Users share their opinions, expressions, and emotions openly on social networking sites. Sometimes, these unabated expressions of feelings and thoughts transcend the limit of decency and lead to swearing, bullying, and character assassination. Harsh and derogatory words are directed toward individuals or groups. Often these acts are termed hate speech. As more and more people gain easy access to the Internet, social media gets flooded with such expressions, comments, and opinions in many diverse languages. It becomes increasingly difficult to police (monitor) such hate speech, especially the posts of multilingual people, which are frequently code-mixed or made up of numerous languages. In order to mitigate the spread of offensive content on social media platforms, the initial step is to detect and identify such textual content. Manually identifying hate speech or bullying in code-mixed languages, if not impossible, is a time-consuming and arduous task. Automating this task involves substantial complications and challenges due to the variety and volume of the data. In a multi-lingual code-mixed environment with multiple languages and scripts, the task becomes even more difficult. This chapter begins with different initiatives and approaches related to the identification of offensive content and hate speech in the English language and then we study their applications on code-mixed data. We evaluate the limitations found in the current state-of-the-art techniques, which demonstrate proficiency in handling text data written in a single language and script. Subsequently, we delve into the challenges associated with processing multi-lingual content. We list down different sources of code-mixed datasets and challenges faced during the processing of the data of multilingual content. We attempt to delineate the timeline with respect to the development of models on hate speech recognition for code-mixed data (with all their advantages, data pre-processing techniques, and limitations), Starting with machine learning (ML) and deep learning (DL) approaches, additional textual representation techniques are increasingly added. We then move on to the multilingual pre-trained models (for example, mBERT, XLMR, MuRIL) for text classification. To corroborate our discussion, we consider a specific dataset (ICHCL 2021, 2022) as a case study for analyzing and identifying hate content from code-mixed online datasets, which are conversational in nature. In addition to considering only single-stand-alone sentences where a sentence holds the context by itself, cases, where previous conversations and the chronology of messages are also taken into account, are discussed. In the end, we discuss the shortcomings of the existing techniques and provide directions for future work.